
みなさん、こんにちは。いし(@ishilog2)です。
今回はPythonを用いて、Yahoo SportsNaviから海外サッカーの順位表をスクレイピングにて取得したいと思います。
[st_toc]導入編
今回のコードではrequestsとBeautifulSoup、Pandasを使用します。
インストールしていない方はインストールして下さい。
pip install requests pip install beautifulsoup4 pip install pandas
実践
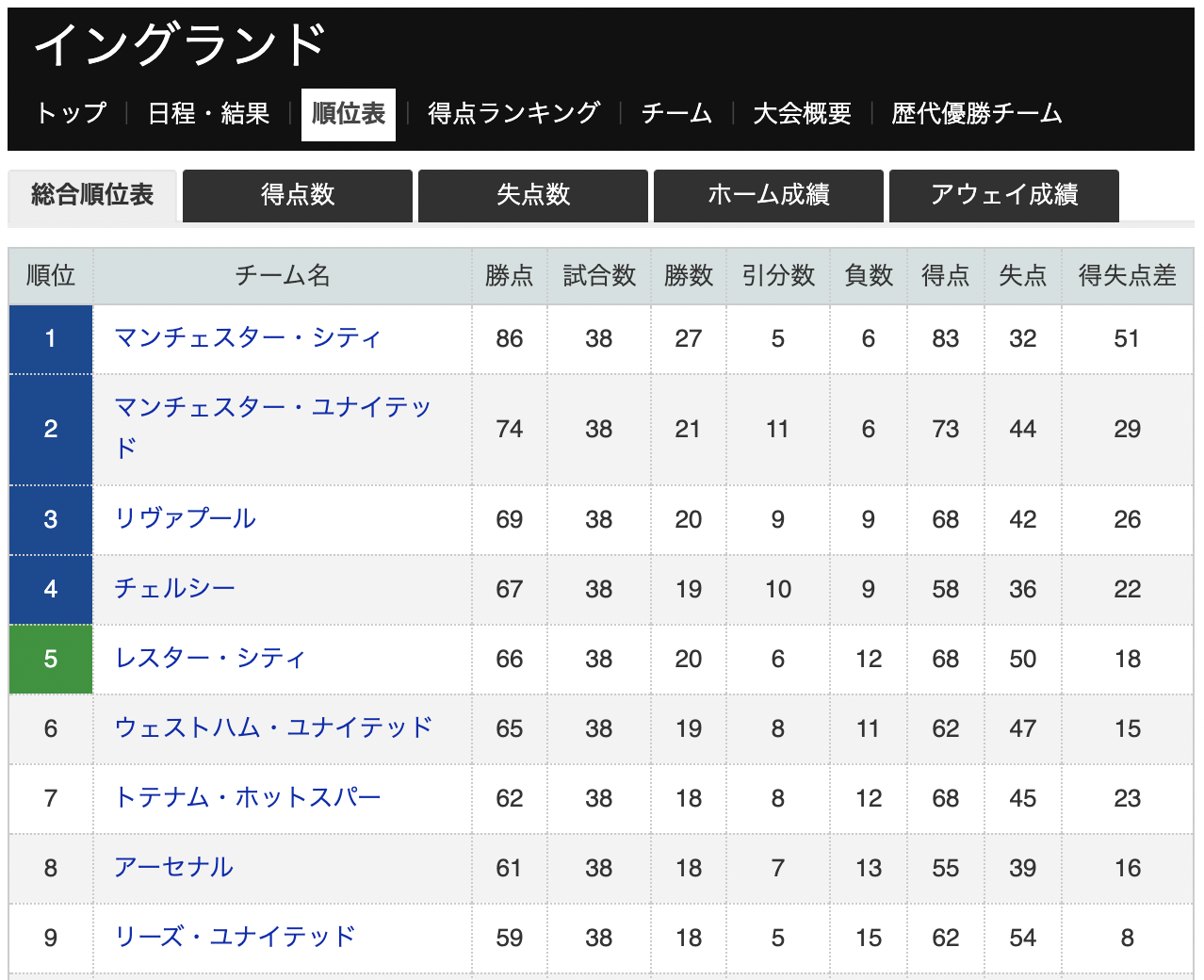
スポーツナビ(https://soccer.yahoo.co.jp/ws/standings/52)から順位表を取得します。
サンプルコード
import requests
from bs4 import BeautifulSoup
import pandas as pd
def WorldSoccreStanding(LeagueCode):
r = requests.get("https://soccer.yahoo.co.jp/ws/standings/" + str(LeagueCode))
soup = BeautifulSoup(r.text, "html.parser")
rs = soup.find("div", class_="sn-table sn-table--ranking")
rs = [i.strip() for i in rs.text.splitlines()]
rs = [i for i in rs if i != ""] rs = [rs[i:i + 10] for i in range(0, len(rs), 10)]
df = pd.DataFrame(rs[1:-1], columns = rs[0])
print(df)
WorldSoccreStanding(52)
このサンプルを使用すると次のような結果が取得できます。
順位 チーム名 勝点 試合数 勝数 引分数 負数 得点 失点 得失点差 0 1 マンチェスター・シティ 86 38 27 5 6 83 32 51 1 2 マンチェスター・ユナイテッド 74 38 21 11 6 73 44 29 2 3 リヴァプール 69 38 20 9 9 68 42 26 3 4 チェルシー 67 38 19 10 9 58 36 22 4 5 レスター・シティ 66 38 20 6 12 68 50 18 5 6 ウェストハム・ユナイテッド 65 38 19 8 11 62 47 15 6 7 トテナム・ホットスパー 62 38 18 8 12 68 45 23 7 8 アーセナル 61 38 18 7 13 55 39 16 8 9 リーズ・ユナイテッド 59 38 18 5 15 62 54 8 9 10 エヴァートン 59 38 17 8 13 47 48 -1 10 11 アストン・ヴィラ 55 38 16 7 15 55 46 9 11 12 ニューカッスル・ユナイテッド 45 38 12 9 17 46 62 -16 12 13 ウルヴァーハンプトン・ワンダラーズ 45 38 12 9 17 36 52 -16 13 14 クリスタル・パレス 44 38 12 8 18 41 66 -25 14 15 サウザンプトン 43 38 12 7 19 47 68 -21 15 16 ブライトン・アンド・ホーヴ・アルビオン 41 38 9 14 15 40 46 -6 16 17 バーンリーFC 39 38 10 9 19 33 55 -22 17 18 フラム 28 38 5 13 20 27 53 -26 18 19 ウェスト・ブロムウィッチ・アルビオン 26 38 5 11 22 35 76 -41 19 20 シェフィールド・ユナイテッド 23 38 7 2 29 20 63 -43
解説
① requestsを用いてHTMLを取得
r = requests.get("https://soccer.yahoo.co.jp/ws/standings/" + str(LeagueCode))
requests.get(‘URL’)でYahoo天気のHTML情報を全て取得します。取得した内容を変数rに格納しています。
② BeautifulSoupを使用してhtml形式にパース
soup = BeautifulSoup(r.text, "html.parser")
①で習得したHTMLからBeautifulSoupオブジェクトを作成します。
[st-mybox title=”パース(parse)とは” fontawesome=”fa-file-text-o” color=”#757575″ bordercolor=”” bgcolor=”#fafafa” borderwidth=”0″ borderradius=”5″ titleweight=”bold” fontsize=”” myclass=”st-mybox-class” margin=”25px 0 25px 0″]自分の環境で扱えるように解析、変換することをparseと言います。そしてパースする処理をまとめたプログラムのことをパーサー(parser)といいます。今回使用しているBeautifulSoupはこのパーサーとなります。
[/st-mybox]
③ データの抽出
rs = soup.find("div", class_="sn-table sn-table--ranking")
「sn-table sn-table–ranking」というクラスの内容を変数rsに格納します。rsはリスト型となります。
④ リストの加工
このままだとリスト内に不要データが多いため無駄なデータを省いていきます。
rs = [i.strip() for i in rs.text.splitlines()]
リスト内表記を使用して、splitlines()で改行コードで分割し、strip()で文字列の前後の空白を削除します。
続いてリスト内の空白要素を削除します。
rs = [i for i in rs if i != ""]
最後に順位・チーム名・勝点・試合数・勝数・引分数・負数・得点・失点・得失点差となるようにリストを10個ずつに分割します。
rs = [rs[i:i + 10] for i in range(0, len(rs), 10)]
⑥ リストをデータフレームへ変換
df = pd.DataFrame(rs[1:-1], columns = rs[0])
pd.DataFrame()でリストからデータフレームへ変換します。
リスト1つ目はヘッダーのためrs[1:-1]で2つ目からをデータフレームにしています。カラムにはリスト1つ目を設定します。
【おまけ】各リーグコード
| 国 | リーグ名 | 番号 |
| イングランド | プレミアリーグ | 52 |
| スペイン | ラ・リーガ | 67 |
| ドイツ | ブンデスリーガ | 56 |
| イタリア | セリエA | 53 |
| フランス | リーグアン | 54 |
| オランダ | エールディビジ | 2 |
| ベルギー | ベルギーリーグ | 48 |
| ポルトガル | ポルトガル・リーグ | 69 |









