
皆さんこんにちは。いし(@ishilog2)です。
今回はPythonを用いて、Yahoo天気からデータ取得したいと思います。
スクレイピングが禁止されているWEBページもあるのでお気を付けください。
スポンサーリンク
事前準備
今回のサンプルではrequestsとBeautifulSoup,Pandasを使用します。
インストールしていない方はインストールして下さい。
pip install requests pip install beautifulsoup4 pip install pandas
実践
実施すること
YahooニュースからトップニュースのタイトルとURLを取得します。
https://news.yahoo.co.jp/
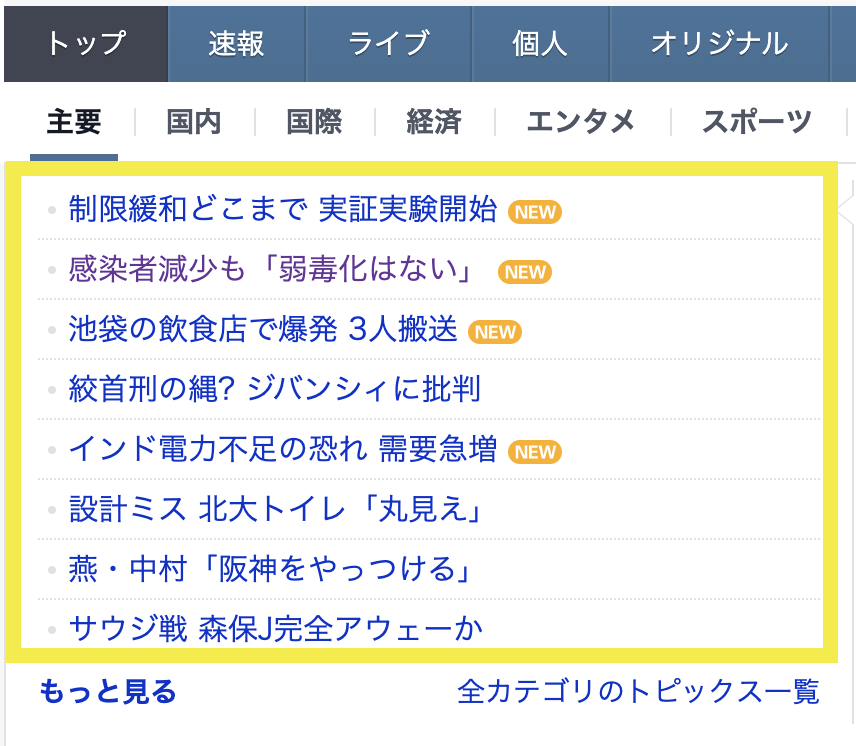
上記画像の黄色の枠内をスクレイピングします。
サンプルコード
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
def main():
url = "https://news.yahoo.co.jp/"
r = requests.get(url)
soup = BeautifulSoup(r.text, "html.parser")
rs = soup.find_all(href=re.compile('news.yahoo.co.jp/pickup'))
df = pd.DataFrame(index=[], columns=['text', 'link'])
for i in rs:
text = i.getText()
link = i.attrs['href']
index = pd.Series([text, link], index=df.columns)
df = df.append(index, ignore_index=True)
print(df)
if __name__=="__main__":
main()
このサンプルを使用すると次のような結果が取得できます。
text link 0 制限緩和どこまで 実証実験開始 https://news.yahoo.co.jp/pickup/6406326 1 感染者減少も「弱毒化はない」 https://news.yahoo.co.jp/pickup/6406322 2 池袋の飲食店で爆発 3人搬送 https://news.yahoo.co.jp/pickup/6406327 3 絞首刑の縄? ジバンシィに批判 https://news.yahoo.co.jp/pickup/6406317 4 インド電力不足の恐れ 需要急増 https://news.yahoo.co.jp/pickup/6406319 5 設計ミス 北大トイレ「丸見え」 https://news.yahoo.co.jp/pickup/6406321 6 燕・中村「阪神をやっつける」 https://news.yahoo.co.jp/pickup/6406320 7 サウジ戦 森保J完全アウェーか https://news.yahoo.co.jp/pickup/6406318
解説
① requestsを用いてHTMLを取得
url = "https://news.yahoo.co.jp/" r = requests.get(url)
requests.get(‘URL’)でYahoo天気のHTML情報を全て取得します。取得した内容を変数rに格納しています。
② BeautifulSoupを使用してhtml形式にパース
soup = BeautifulSoup(r.text, 'html.parser')
①で習得したHTMLからBeautifulSoupオブジェクトを作成します。
③ データの抽出
rs = soup.find_all(href=re.compile('news.yahoo.co.jp/pickup'))
“news.yahoo.co.jp/pickup'”というリンクが付いている内容を変数rsに格納します。
④ 空のデータフレームの作成
df = pd.DataFrame(index=[], columns=['text', 'link'])
保存用するためのデータフレームを作成します。
⑤ データフレームへ見出しとURLを追加
for i in rs:
text = i.getText()
link = i.attrs['href']
index = pd.Series([text, link], index=df.columns)
df = df.append(index, ignore_index=True)
ABOUT ME
スポンサーリンク
スポンサーリンク










