
ヤマトのWEBページリニューアルに対応して内容修正しました。
https://faq.kuronekoyamato.co.jp/app/customer/detail/a_id/3579
みなさん、こんにちは。いし(@ishilog2)です。
今回はPythonを用いて、ヤマト運輸から荷物状況をスクレイピングにて取得したいと思います。
[st_toc]導入編
今回のコードではrequestsとBeautifulSoup、Pandasを使用します。
インストールしていない方はインストールして下さい。
pip install requests pip install beautifulsoup4 pip install pandas
実践
実施すること
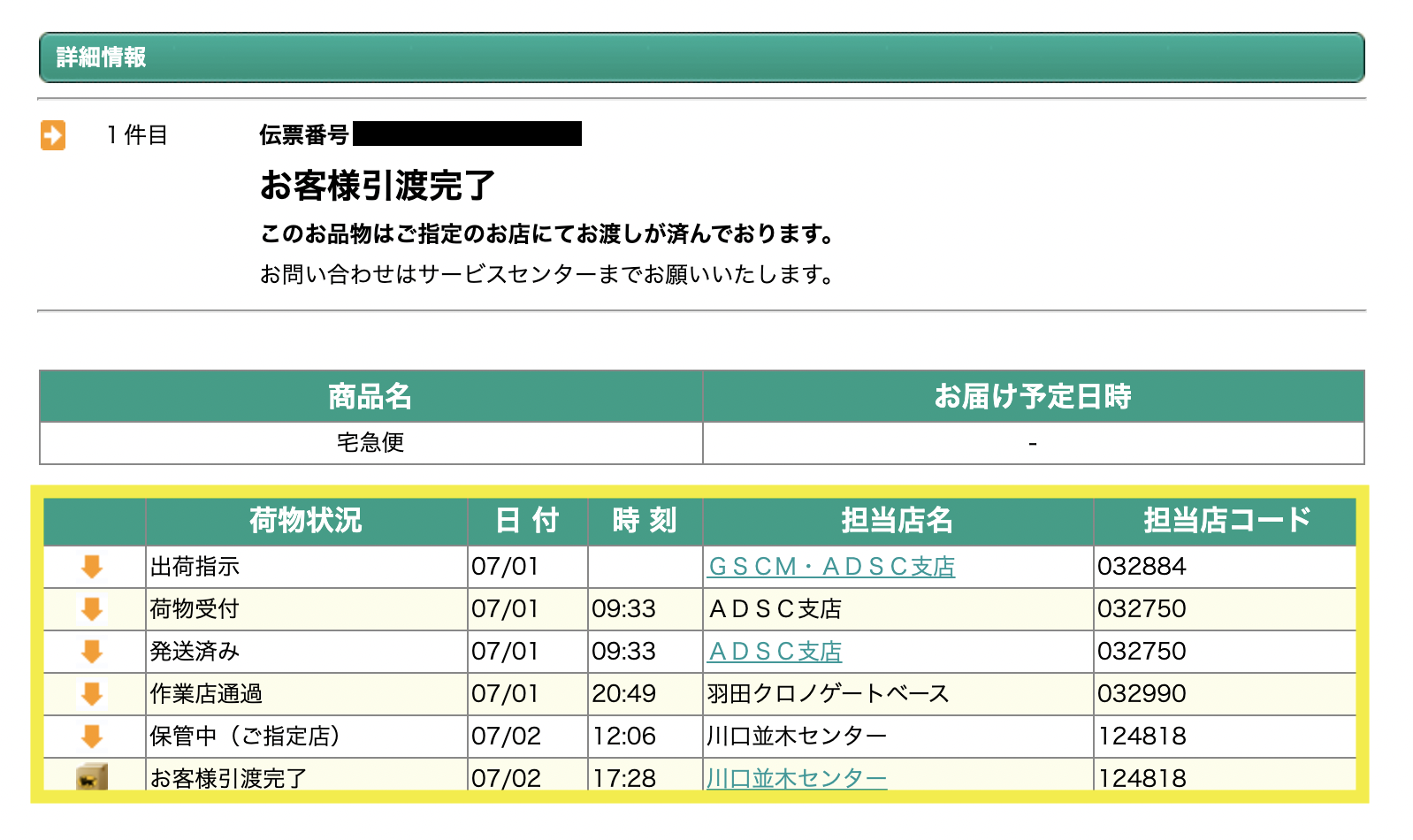
ヤマトの追跡サイトから画像の黄枠内の情報を取得します。
https://toi.kuronekoyamato.co.jp/cgi-bin/tneko
サンプルコード
新コード
import requests
from bs4 import BeautifulSoup
import pandas as pd
def YamatoTracking(TrackingCode):
url = "https://toi.kuronekoyamato.co.jp/cgi-bin/tneko"
r = requests.post(url, {"number01":TrackingCode, "number00":1})
soup = BeautifulSoup(r.text, "html.parser")
rs = soup.find("div", class_="tracking-invoice-block-detail") #修正箇所
rs = [i for i in rs.text.splitlines()]
rs = [rs[3:][idx:idx + 5] for idx in range(0,len(rs[3:]), 5)] #修正箇所
df = pd.DataFrame(rs[1:], columns = rs[0])
print(df)
YamatoTracking(XXXXXXXXXXXX)
旧コード
import requests
from bs4 import BeautifulSoup
import pandas as pd
def YamatoTracking(TrackingCode):
url = "https://toi.kuronekoyamato.co.jp/cgi-bin/tneko"
r = requests.post(url, {"number01":TrackingCode, "number00":1})
soup = BeautifulSoup(r.text, "html.parser")
rs = soup.find("table", class_="meisai")
rs = [i for i in rs.text.splitlines()]
rs = [rs[3:][idx:idx + 8] for idx in range(0,len(rs[3:]), 8)]
df = pd.DataFrame(rs[1:], columns = rs[0])
print(df)
YamatoTracking(xxxxxxxxxxxx)
xxxxxxxxxxxxには追跡番号を入れてください。
このサンプルを使用すると次のような結果が取得できます。
荷物状況 日 付 時 刻 担当店名 担当店コード 0 出荷指示 07/01 GSCM・ADSC支店 032884 1 荷物受付 07/01 09:33 ADSC支店 032750 2 発送済み 07/01 09:33 ADSC支店 032750 3 作業店通過 07/01 20:49 羽田クロノゲートベース 032990 4 保管中(ご指定店) 07/02 12:06 川口並木センター 124818 5 お客様引渡完了 07/02 17:28 川口並木センター 124818
解説
① requestsを用いてHTMLを取得
url = "https://toi.kuronekoyamato.co.jp/cgi-bin/tneko"
r = requests.post(url, {"number01":TrackingCode, "number00":1})
requests.get(‘URL’)でHTML情報を全て取得します。取得した内容を変数rに格納しています。
”number00”:1の部分は○件目です。今回のサンプルは1件しか取得しないので1で固定しています。
② BeautifulSoupを使用してhtml形式にパース
soup = BeautifulSoup(r.text, "html.parser")
①で習得したHTMLからBeautifulSoupオブジェクトを作成します。
[st-mybox title=”パース(parse)とは” fontawesome=”fa-file-text-o” color=”#757575″ bordercolor=”” bgcolor=”#fafafa” borderwidth=”0″ borderradius=”5″ titleweight=”bold” fontsize=”” myclass=”st-mybox-class” margin=”25px 0 25px 0″]自分の環境で扱えるように解析、変換することをparseと言います。そしてパースする処理をまとめたプログラムのことをパーサー(parser)といいます。今回使用しているBeautifulSoupはこのパーサーとなります。
[/st-mybox]
③ データの抽出
rs = soup.find("table", class_="meisai")
「meisai」というクラスの内容を変数rsに格納します。rsはリスト型となります。
④ リストの加工
rs = [i for i in rs.text.splitlines()]
リスト内表記を使用して、習得したデータをリストに格納・リスト内の要素の前後にある空白を削除します。splitlines()で改行コードで分割しています。
続いて荷物状況・日 付・時 刻・担当店名・担当店コード となるようにリストを分割します。
この際に先頭の3個を削除して8個ずつとします。
rs = [rs[3:][idx:idx + 8] for idx in range(0,len(rs[3:]), 8)]
⑤ リストをデータフレームへ変換
df = pd.DataFrame(rs[1:], columns = rs[0])
pd.DataFrame()でリストからデータフレームへ変換します。
リスト1つ目はヘッダーのため2つ目からをデータフレームにしています。カラムにはリスト1つ目を設定します。
ターミナルから実行するサンプル
import requests
from bs4 import BeautifulSoup
import pandas as pd
import sys
def main():
args = sys.argv
TrackingCode = args[1]
url = "https://toi.kuronekoyamato.co.jp/cgi-bin/tneko"
r = requests.post(url, {"number01":str(TrackingCode), "number00":1})
soup = BeautifulSoup(r.text, "html.parser")
rs = soup.find("div", class_="tracking-invoice-block-detail")
if rs == None:
print("追跡番号の情報がありません。")
else:
rs = [i for i in rs.text.splitlines()]
rs = [rs[3:][idx:idx + 5] for idx in range(0,len(rs[3:]), 5)]
df = pd.DataFrame(rs[1:], columns = rs[0])
print(df)
if __name__=="__main__":
main()
ターミナル(コマンドプロント)等で下記のコマンドを実行してください。
python3 yamato.py xxxxxxxxxxxx
python3 + ファイル名 + 追跡番号を入力してください。










